SpringMVC处理请求源码分析——part3补充功能
Spring MVC源码分析分为三个部分,如果你还没看过前两部分,那我建议你按顺序看完前面的再看这个。
SpringMVC处理请求源码分析——part1 整体流程 - coderZoe的博客
SpringMVC处理请求源码分析——part2 场景分析 - coderZoe的博客
前两个部分在9月初就总结完了,但直到马上12月了第三个部分还没出来。主要是我最近有点太懒了,经过一番痛定思痛,于是part3也出来了,part3补充功能主要想跟大家讲两个内容,文件上传和拦截器。
1. 文件上传
我们先从文件上传说起,相信大家都写过这样的代码:
@PostMapping("/file")
public String upload(MultipartFile file){
//...
return "ok";
}其中参数MultipartFile是SpringMVC为我们提供的,SpringMVC会将HTTP请求传入的文件转为MultipartFile对象,我们直接操作这个对象即可。但我们不禁要问,SpringMVC是如何做的呢?在文件上传的时候,SpringMVC帮我们做了哪些事情呢?要回答这个问题还是得回到梦开始的地方:DispatcherServlet#doDispatch()
我们之前已经在前面两篇文章讲了DispatcherServlet#doDispatch()的大体流程,这里不妨再拿过来,不过这里我们需要细化一点关于文件上传的东西:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
//...
//文件上传的处理
boolean multipartRequestParsed = false;
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request);
ModelAndView mv = null;
//找到处理方法
mappedHandler = getHandler(processedRequest);
//...
//找到处理方法的适配器
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
//...
//解析参数,执行方法,并处理方法的返回
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
//...
//视图解析
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
//...
//文件资源的释放
if (multipartRequestParsed) {
cleanupMultipart(processedRequest);
}
}可以看到,这里面最核心的代码是checkMultipart(request),我们不妨点进源码:
protected HttpServletRequest checkMultipart(HttpServletRequest request) throws MultipartException {
if (this.multipartResolver != null && this.multipartResolver.isMultipart(request)) {
//...
return this.multipartResolver.resolveMultipart(request);
//...
}
// If not returned before: return original request.
return request;
}首先multipartResolver就是文件解析器,DispatcherServlet对象持有multipartResolver属性,if语句会先判断当前HTTP请求是否是文件,如果是文件则用文件解析器来解析HTTP请求。
public class DispatcherServlet extends FrameworkServlet {
//...
@Nullable
private MultipartResolver multipartResolver;
//...
}其中multipartResolver的具体实现类为StandardServletMultipartResolver,因此StandardServletMultipartResolver的isMultipart()判断内容如下:
public boolean isMultipart(HttpServletRequest request) {
return StringUtils.startsWithIgnoreCase(request.getContentType(),
(this.strictServletCompliance ? MediaType.MULTIPART_FORM_DATA_VALUE : "multipart/"));
}简单来讲就是判断当前HTTP请求的contentType是否是以multipart/开头的(严格模式下是以multipart/form-data开头),我们知道,如果前端传文件,则HTTP请求的请求往往是multipart/form-data,因此 如果请求的参数包含文件,这个if语句肯定是判断为true的
再往下走就是使用文件解析器来解析HTTP请求,也即:
return this.multipartResolver.resolveMultipart(request);很明显,上面的代码就是最核心的文件解析,StandardServletMultipartResolver#resolveMultipart()源码内容如下:
public MultipartHttpServletRequest resolveMultipart(HttpServletRequest request) throws MultipartException {
return new StandardMultipartHttpServletRequest(request, this.resolveLazily);
}public StandardMultipartHttpServletRequest(HttpServletRequest request, boolean lazyParsing)
throws MultipartException {
super(request);
if (!lazyParsing) {
parseRequest(request);
}
}其中resolveLazily默认是false,resolveLazily代表是否懒解析,也即是否到参数需要文件的时候再解析,默认为false。因此我们会在这里直接解析,解析的核心也很简单,就是将当前HTTP请求对象包装为一个更复杂的的HTTP请求对象:StandardMultipartHttpServletRequest,这个对象在我们原来的HTTP请求对象的基础上多了一个关键的属性:multipartFiles
public abstract class AbstractMultipartHttpServletRequest extends HttpServletRequestWrapper
implements MultipartHttpServletRequest {
@Nullable
private MultiValueMap<String, MultipartFile> multipartFiles;
//...
}AbstractMultipartHttpServletRequest是StandardMultipartHttpServletRequest的抽象父类。
multipartFiles属性是个Map,Map的key为文件名,value为MultipartFile对象,MultipartFile对象大家应该已经很熟悉了。补充一句的是这是个MultiValueMap,也即允许一个key对应多个value,也即允许多个同名的文件上传。
很明显我们也可以得出结论,所谓文件解析,就是构造那么一个StandardMultipartHttpServletRequest对象,并从当前HTP请求中将文件解出来赋值给multipartFiles属性,这样在HandlerAdapter做参数解析的时候就可以直接从StandardMultipartHttpServletRequest中拿出文件信息赋值给我们的参数了。
那么就让我们看下文件解析器是如何解析文件的:
private void parseRequest(HttpServletRequest request) {
try {
//从原始的HTTP请求中得到Part,Part其实就可以认为是文件对象了
Collection<Part> parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet<>(parts.size());
//files对象就是用来存储解析结果的
MultiValueMap<String, MultipartFile> files = new LinkedMultiValueMap<>(parts.size());
//遍历parts
for (Part part : parts) {
//下面三行代码是要拿到文件名
String headerValue = part.getHeader(HttpHeaders.CONTENT_DISPOSITION);
ContentDisposition disposition = ContentDisposition.parse(headerValue);
String filename = disposition.getFilename();
//如果文件名存在
if (filename != null) {
//做一下文件名的特殊处理
if (filename.startsWith("=?") && filename.endsWith("?=")) {
filename = MimeDelegate.decode(filename);
}
//将文件加入到files中,其中key为文件名,value就是StandardMultipartFile对象
files.add(part.getName(), new StandardMultipartFile(part, filename));
}
else {
this.multipartParameterNames.add(part.getName());
}
}
//将files对象赋值给multipartFiles属性
setMultipartFiles(files);
}
catch (Throwable ex) {
handleParseFailure(ex);
}
}
//做了一个map的不可修改
protected final void setMultipartFiles(MultiValueMap<String, MultipartFile> multipartFiles) {
this.multipartFiles =
new LinkedMultiValueMap<>(Collections.unmodifiableMap(multipartFiles));
}很明显,最最核心的代码其实就是
Collection<Part> parts = request.getParts();这句话其实就是从HTTP请求中解析出来Part对象,然后取Part对象的各种属性以及将它包装为StandardMultipartFile,最终就是赋值到multipartFiles属性上。
request.getParts()的内容非常长,也非常深,就不带大家一起看了,感兴趣的同学可以自己去看下,这里补充一句的是,有时我们对HTTP请求文件的一些设置,如
spring:
servlet:
multipart:
max-file-size: 1GB其实都是在这里校验的,如果不满足都是在这里抛出来的异常。
下面我们再看下参数解析器是如何将我们解析出来的multipartFiles属性赋值到我们的参数上的。
在我们一开始示例
@PostMapping("/file")
public String upload(MultipartFile file){
//...
return "ok";
}这种写法中,使用的参数解析器为RequestParamMethodArgumentResolver,那么我们必然就需要看下为什么是这个参数解析器,以及这个参数解析器是如何解析的:
public boolean supportsParameter(MethodParameter parameter) {
if (parameter.hasParameterAnnotation(RequestParam.class)) {
if (Map.class.isAssignableFrom(parameter.nestedIfOptional().getNestedParameterType())) {
RequestParam requestParam = parameter.getParameterAnnotation(RequestParam.class);
return (requestParam != null && StringUtils.hasText(requestParam.name()));
}
else {
return true;
}
}
else {
if (parameter.hasParameterAnnotation(RequestPart.class)) {
return false;
}
parameter = parameter.nestedIfOptional();
if (MultipartResolutionDelegate.isMultipartArgument(parameter)) {
return true;
}
else if (this.useDefaultResolution) {
return BeanUtils.isSimpleProperty(parameter.getNestedParameterType());
}
else {
return false;
}
}
}对于文件上传请求,代码会走入上述第16行代码,也即:
if (MultipartResolutionDelegate.isMultipartArgument(parameter)) {
return true;
}判断我们当前的参数是否是一个Multipart参数,判断的方法如下:
public static boolean isMultipartArgument(MethodParameter parameter) {
Class<?> paramType = parameter.getNestedParameterType();
return (MultipartFile.class == paramType ||
isMultipartFileCollection(parameter) || isMultipartFileArray(parameter) ||
(Part.class == paramType || isPartCollection(parameter) || isPartArray(parameter)));
}拿到参数的class,如果是MultipartFile类型,或者是MultipartFile集合类型,再或者是MultipartFile数组类型,亦或者是Part类型、Part集合,Part数组类型都可以。
很明显我们的参数是符合的,因此返回true,也就代表RequestParamMethodArgumentResolver可以解析这种情况,那我们再看下它是如何解析的:
public final Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
//...
//拿到参数名
Object resolvedName = resolveEmbeddedValuesAndExpressions(namedValueInfo.name);
//...
//按参数名解析
Object arg = resolveName(resolvedName.toString(), nestedParameter, webRequest);
//...
}
protected Object resolveName(String name, MethodParameter parameter, NativeWebRequest request) throws Exception {
HttpServletRequest servletRequest = request.getNativeRequest(HttpServletRequest.class);
if (servletRequest != null) {
//按照文件的形式解析参数
Object mpArg = MultipartResolutionDelegate.resolveMultipartArgument(name, parameter, servletRequest);
if (mpArg != MultipartResolutionDelegate.UNRESOLVABLE) {
return mpArg;
}
}
//...
}可以看到上面参数解析,最核心的内容便是MultipartResolutionDelegate.resolveMultipartArgument()
public static Object resolveMultipartArgument(String name, MethodParameter parameter, HttpServletRequest request)
throws Exception {
//将当前HTTP请求按MultipartHttpServletRequest解析
MultipartHttpServletRequest multipartRequest =
WebUtils.getNativeRequest(request, MultipartHttpServletRequest.class);
//判断当前HTTP请求是真的是Multipart,也即传文件的
//这里可能很多人有疑问,直接看前半部分multipartRequest != null不等于空不就行了吗,为什么还要后半部分
//因为我们前面提到了懒解析,如果是懒解析,当前HTTP请求对象不是MultipartHttpServletRequest类型
//但HTTP请求的contentType依然是multipart
boolean isMultipart = (multipartRequest != null || isMultipartContent(request));
//如果当前参数类型是MultipartFile类型
if (MultipartFile.class == parameter.getNestedParameterType()) {
//但当前HTTP请求不是multipart,也即没传来文件,那直接返回null
if (!isMultipart) {
return null;
}
//当前HTTP请求没有解析成MultipartHttpServletRequest
//很明显这是懒解析的场景,因为上面的isMultipart为true才能走到这里,既然HTTP请求是文件请求,但没解析为
//MultipartHttpServletRequest对象,那只能是懒解析,刚才没解析,那就这里解析好了
if (multipartRequest == null) {
multipartRequest = new StandardMultipartHttpServletRequest(request);
}
//从MultipartHttpServletRequest中将文件取出来返回
return multipartRequest.getFile(name);
}
//下面内容都是类似,不再赘述。
else if (isMultipartFileCollection(parameter)) {
if (!isMultipart) {
return null;
}
if (multipartRequest == null) {
multipartRequest = new StandardMultipartHttpServletRequest(request);
}
List<MultipartFile> files = multipartRequest.getFiles(name);
return (!files.isEmpty() ? files : null);
}
else if (isMultipartFileArray(parameter)) {
if (!isMultipart) {
return null;
}
if (multipartRequest == null) {
multipartRequest = new StandardMultipartHttpServletRequest(request);
}
List<MultipartFile> files = multipartRequest.getFiles(name);
return (!files.isEmpty() ? files.toArray(new MultipartFile[0]) : null);
}
else if (Part.class == parameter.getNestedParameterType()) {
if (!isMultipart) {
return null;
}
return request.getPart(name);
}
else if (isPartCollection(parameter)) {
if (!isMultipart) {
return null;
}
List<Part> parts = resolvePartList(request, name);
return (!parts.isEmpty() ? parts : null);
}
else if (isPartArray(parameter)) {
if (!isMultipart) {
return null;
}
List<Part> parts = resolvePartList(request, name);
return (!parts.isEmpty() ? parts.toArray(new Part[0]) : null);
}
else {
return UNRESOLVABLE;
}
}public MultipartFile getFile(String name) {
return getMultipartFiles().getFirst(name);
}
protected MultiValueMap<String, MultipartFile> getMultipartFiles() {
if (this.multipartFiles == null) {
initializeMultipart();
}
return this.multipartFiles;
}这样,其实我们就把SpringMVC解析文件上传讲完了。
2. 拦截器
拦截器是我们在Spring MVC开发中使用的非常频繁的功能,如果我们需要做一些统一处理的时候往往就可以使用拦截器,比如鉴权,日志记录等。
在讲拦截器前我们先回顾一下Spring MVC的处理流程:
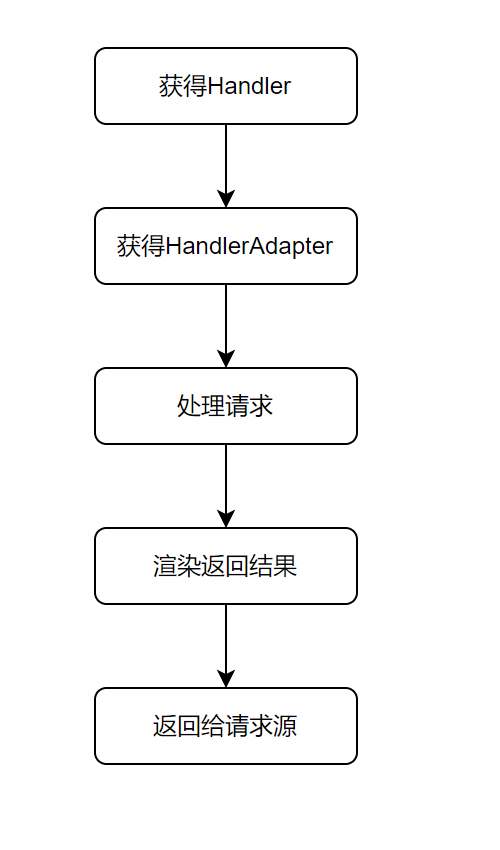
Spring MVC提供的拦截器接口如下:
public interface HandlerInterceptor {
default boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
return true;
}
default void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
@Nullable ModelAndView modelAndView) throws Exception {
}
default void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler,
@Nullable Exception ex) throws Exception {
}
}拦截器里的这些方法都切入到MVC的处理过程中:
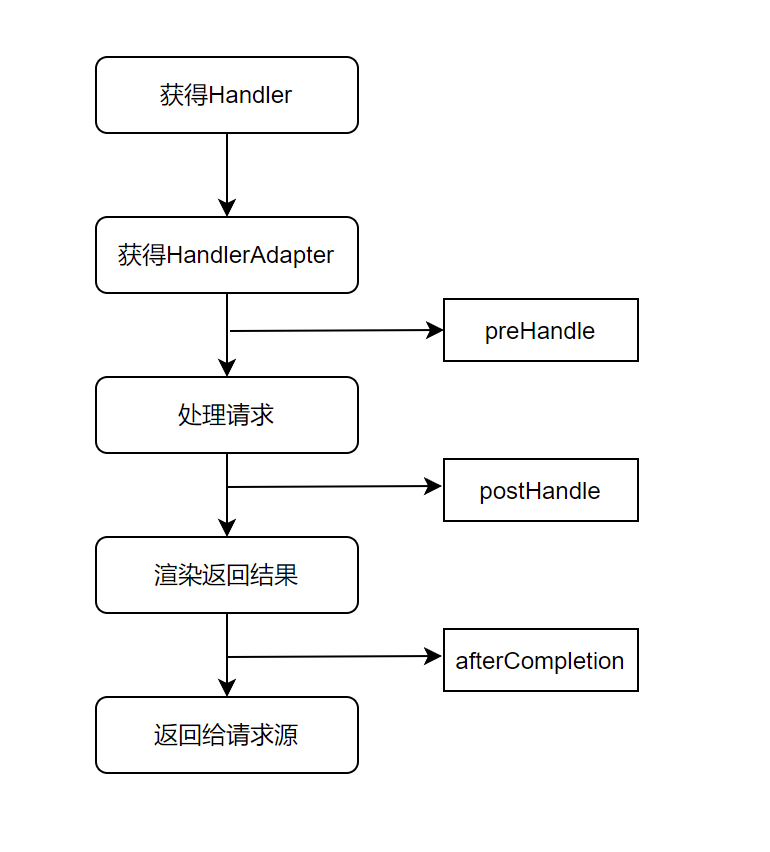
也即preHandle的切入点是在获得适配器以后但实际执行请求处理以前,postHandle是在实际执行处理之后但在渲染返回结果之前,afterCompletion是在渲染返回结果之后,实际返回给请求方之前。
注:上图的拦截器切入流程是不准确的,因为很多时候拦截器是可以短路(拦截)整个处理的,上图我们只是画出了正常情况下的处理,对于更通用的情况会在我们看源码的时候详细的说。
它们对应的源码内容如下:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
//...
ModelAndView mv = null;
mappedHandler = getHandler(processedRequest);
//...
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler());
//...
//拦截器 preHandle方法的执行
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
//...
//拦截器 postHandle方法的执行
mappedHandler.applyPostHandle(processedRequest, response, mv);
//...
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
//拦截器 afterCompletion的执行
//这里的顺序虽然是对的,但triggerAfterCompletion函数会在多处多种情况下被调用,我们下面会说
mappedHandler.triggerAfterCompletion(request, response, null);
//...
}2.1 源码分析
通过上面的方法,我们看到preHandle()方法在找到handler与handlerAdapter之后但实际执行HandlerMethod之前之前被调用。preHandle()接口方法如下:
default boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
return true;
}函数会返回一个boolean值,如果为true则代表前置处理成功,可以放行执行HandlerMethod,否则就代表执行被拦截,不再实际执行HandlerMethod,其中参数Object handler在请求是动态请求(会打到Controller上,由RequestMappingHandlerMapping处理的请求)时,往往实际的类型就是HandlerMethod对象,因此这里其实可以做强转。
很明显,preHandle()更适合做统一拦截,如鉴权的时候判断用户是否有权限,如果没有权限就直接拦截驳回即可。
现在我们看下,DispatcherServlet中对它的调用源码:
首先我们需要先知道applyPreHandle()的HandlerExecutionChain内部方法:
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerExecutionChain mappedHandler = null;
mappedHandler = getHandler(processedRequest);
if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
}
}HandlerExecutionChain内部有几个重要的属性:
public class HandlerExecutionChain {
private final Object handler;
private final List<HandlerInterceptor> interceptorList = new ArrayList<>();
private int interceptorIndex = -1;
}其中handler往往就是我们的HandlerMethod,而interceptorList就是属于当前handler的拦截器对象,一个请求可以有多个拦截器,它们是有序的。interceptorIndex属性很关键,它指向的是当前执行到的拦截器位置,这在我们讲整个拦截器处理流程中异常重要。
现在我们看下applyPreHandle()的源码:
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
for (int i = 0; i < this.interceptorList.size(); i++) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
this.interceptorIndex = i;
}
return true;
}可以看到比较简单,就是遍历interceptorList,挨个执行这些拦截器的preHandle()方法。但这里有两点十分重要的内容:
- 如果当前拦截器的
preHandle()返回true,则interceptorIndex记录遍历的拦截器位置。 - 如果拦截器的
preHandle()有一个返回false,就直接执行triggerAfterCompletion()方法,然后整个处理流程就结束了。
为什么要记录执行到的拦截器的位置?我们看下triggerAfterCompletion()的源码就明白了:
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, @Nullable Exception ex) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
try {
interceptor.afterCompletion(request, response, this.handler, ex);
}
catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}可以看到triggerAfterCompletion()就是遍历执行拦截器的afterCompletion()方法,但它的执行顺序有些不同,它是从interceptorIndex开始,倒序的方式执行。
假设我们现在写了3个拦截器,它们的顺序分别是A、B、C。假设现在A、B的preHandle()返回的是true,但C返回的是false。一个请求过来后,会先执行A的preHandle()方法,此时interceptorIndex更新为0(A在数组的第一个位置);然后执行B,将interceptorIndex更新为1;最后执行C的preHandle(),返回为false,终止执行。调用triggerAfterCompletion(),此时triggerAfterCompletion()会从B开始执行B的afterCompletion(),然后再执行A的afterCompletion()。
看明白了吗?interceptorIndex是用于记录当前拦截器是在执行到第几个出问题的,一旦出了问题,就从出问题前的那一个拦截器开始倒序执行afterCompletion()方法。
如果都没有问题(preHandle()均返回的true),那interceptorIndex就更新为最后那个拦截器的位置。然后使用handlerAdapter来实际的执行HandlerMethod,如果执行没有异常,则会执行拦截器的postHandle()方法。其源码如下:
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, @Nullable ModelAndView mv)
throws Exception {
for (int i = this.interceptorList.size() - 1; i >= 0; i--) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
interceptor.postHandle(request, response, this.handler, mv);
}
}需要先明确的是,会执行到postHandle()则代表:
- 当前方法所属所有拦截器的
preHandle()都返回的true HandlerMethod的执行没有出错
applyPostHandle()的执行也比较简单,就是挨个遍历每个拦截器,然后执行它们的postHandle()方法,但是需要注意的是,这里的执行是倒序执行的,也即对于拦截器A、B、C,它们的preHandle()执行顺序是A、B、C,但postHandle()是C、B、A的顺序执行。
最后,当所有处理均执行完(做完数据和视图的处理了)或者整个doDispatch()的执行出现任何异常,都会调用DispatcherServlet#triggerAfterCompletion(),尝试执行拦截器的afterCompletion方法。
这里的异常包括但不限于:
getHandler()找HandlerMethod出现异常(更具体地说是找HandlerExecutionChain)getHandlerAdapter()找HandlerAdapter出现异常- 执行拦截器的
preHandle()出现异常 - 实际执行
HandlerMethod出现异常 - 执行拦截器的
postHandle()出现异常 - 数据和视图的解析渲染出现异常
而DispatcherServlet#triggerAfterCompletion()的源码如下:
private void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response,
@Nullable HandlerExecutionChain mappedHandler, Exception ex) throws Exception {
if (mappedHandler != null) {
mappedHandler.triggerAfterCompletion(request, response, ex);
}
throw ex;
}可以看到会先判断是否找到了HandlerExecutionChain(因为我们上面说了getHandler()也可能会出现异常),如果找到了就调用它的triggerAfterCompletion()。
HandlerExecutionChain#triggerAfterCompletion()的源码我们其实上面已经看过了:
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, @Nullable Exception ex) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = this.interceptorList.get(i);
try {
interceptor.afterCompletion(request, response, this.handler, ex);
}
catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}就是从interceptorIndex开始倒序执行拦截器的afterCompletion()方法。
2.2 总结
拦截器的执行源码其实还是很简单的,大家需要自己手动的翻一翻看一看。总的来说就是会先正序的执行每个拦截器的preHandle(),如果有任何异常(包括返回false),就直接从那个异常的拦截器之前开始,倒序执行它们的afterCompletion()方法。如果没有异常,且使用适配器执行完了处理方法,就再倒叙的执行每个拦截器的postHandle()方法。然后执行ModelAndView的解析和渲染,最终如果均没有异常或者再任何一步出现异常,都会倒序的执行拦截器的afterCompletion()方法。
